Introduction
It is a project to use Convolutional Neural Network(CNN) to recognize how many objects are in a 3D image and determine the superficial areas for all the things. In the first step, only spheres are applied in embodiments.
Therefore, the first step has two tasks. 1, creating the dataset with TomoPhantom; 2, designing and training the CNN network. One of the challenges is that the images can have multiple spheres, and the output needs to recognize how many spheres are there in the image with each of their sizes. Image classification can be employed in this case, but with the number of spheres increasing, it is not an ideal plan to have all possible classes for each image group. Object Recognition or Object Detection might be better operations, but the output has to be a conclusion instead of operated images. We might need a new network to hybridize these.
TomoPhantom can be used to generate the images. Second, the superficial areas will be labeled for the training dataset. Then train a Convolutional Neural Network to find out the external size of spheres.
Generate Spheres in 3D Images
There is a paper introduced about TomoPhantom. TomoPhantom, a software package to generate 2D–4D analytical phantoms for CT image reconstruction algorithm benchmarks. This paper introduced the advantages of TomoPhantom and some examples to employ it. With TomoPhantom, models and objects can be generated. Model is a group objects created together. If yoou have a special of group objects need to be quoted multiple times, you should generate with a model. I recommend to check Phantom3DLibrary.dat to understand generate models. This page has the settings for all of the models avaliable with Tomo’s library. For this porject, we only need to gererate objects. We can use the model to create random spheres, such as hundreds of spheres in one model, but it is not necessary. For function Objects3D, there are 6 modes can be chosen: “CONE”, “CUBOID”,”ELLIPCYINEDER”,”ELLIPSOID”, “GAUSSIAN”, “PARABOLOID”. We only need “ELLIPSOID” for this project. ‘x0’,’y0’,’z0’, in the range of [-1.0,1.0], set up the location. ‘a’,’b’,’c’, in the range of [0,1], set up the size of the object. ‘phi1’ is the angle.
Machine Vision Technology
There are some popular Machine Vision technology, such as Image Classification, Image Reconstruction, Deblurring, Denoise, Image Segmentation, Visual Odometry, Object Detection , and Object Recognition. Object Detection, Visual Odometry, and Object Recognition are the topics I haven’t used before. However, this project is special from any work I have learned. Personally, Image Classification and Object Recognition can be emploied in this project. Both of them have their advantages and weakpoints.
First of all, let’s check Object Recognition and notice the difference between it and Object Detection. The resouse is from this link.Object Recognition is used to answer this question: which object is depicted in the image? Object Detection, on other hand, is answering: where is this object in the image? Input for Object Recognition is images with unknown objects. The output for it is the positions and labels. In a simple way, Object Recognition is “a combined task of object detection plus image classification”
Under Object Detection topic, SSD, RetinaNetYou Only Look Once(YOLO) are some of the most famorous algorithm.
Data Storing
After creating the images, they need to be stored and to be built into a reusable database. For most medical 3D images are stolded into Nifti format, Minc format, or Dicom format. Nifti format is common to be used for CNN.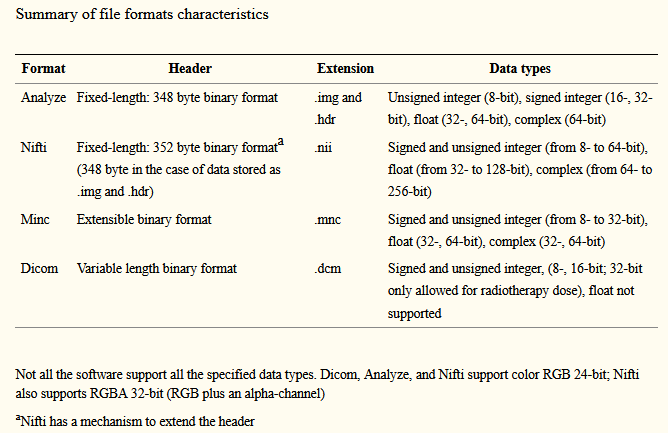
There are some popular 3D images database such as modelNet10, which is using .OFF file format. Some database are real photos with objects in different angles such as ObjectNet3D, MVTecITODD, and T-LESS. HDF5 is another format for storing. With Matlab, .mat might be another operation.
Data Format for this project
For 3D-Bat, the free label program, it apply the data format PCD(Point Cloud Data). This bring us to another topic for Point Cloud Data.
JSON, PKL, TFRecord
The images are simulating a 10cm10cm10cm space. The image itself is 128^3 voxels 3D image. 10mm radius uses 12 picels. 5mm uses 6 pixels. 2.5mm use 3 pixels. That means except the spheres most part of image will be empty. In this case, OctNet is an arithmetic can help optimize the storage space and training time. It created an unbalanced octrees arithmetic to hierarchically partition sparse 3D image. With OctNet, this project might can increase resolutions to 256^3 voxels. However, files with OctNet need to convert into 3D arraies again to applied in some programs such as Matlab. It might be complex for this project to use it. The following image is the main idea for OctNet.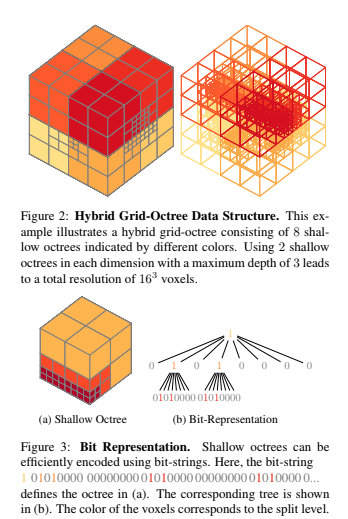
Building Datasets
Image Classification:
pros: It does not need special labels. Group data into different classifications with name or folders, computer can identify testing data into different classes.
cros: It might need too many classes as this project’s requirements. Multiple spheres need different group for each type. For example, one 1mm-radius sphere and two 1mm-radius spheres needs to be classified into two different groups. This project has three different size of spheres. If it need to have three spheres in one image, it totally need 16 groups, which might be too many.
Object Detection:
pros: Following objects instead of whole image. It can be emploied for more spheres situation. Also can be applied for video and others.
cros: Each object need to be labelled in boxes for training data.
Object Recognition:
pros:
cros:
Label Tool
There is a list of image label tools: V7, Labelbox, Scale AI, SuperAnnotate, DataLoop, Playment, Deepen, Supervise.ly, Hive Data, (following are free tools) CVAT, LabelMe, Labelimg, VoTT, ImgLab. A free tool which also works for 3D image is 3D-Bat.
Following reed me to instal and label step by step. PHP Storm or WebStorm can be free with .edu email address. With the license all the app from JetBrains can be used freely.
Images Classification
Object Detection
Object Recognition
Future Works
Image generate: More various and complex objects should be created instead of only has spheres to similate droplet. Learning a Probabilitic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. This paper introduced gereate 3D images from input 2D image with CNN. With this technic it can be easier to expand dataset for this project.
Data Storing:
New CNN models:
References
- Medical Image File Formats,Michele Larobina and Loredana Murino ,https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3948928/
- ObjectNet3D:A Large Scale Database for 3D Object Recognition,Yu Xiang, Wonhui Kim, etc.,https://cvgl.stanford.edu/projects/objectnet3d/
- Image Data Labelling and Annotation – Everything you need to know, Sabina Pokhrel, https://towardsdatascience.com/image-data-labelling-and-annotation-everything-you-need-to-know-86ede6c684b1
- You Only Look Once: Unified, Real-Time Object Detection, Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
- Expandable YOLO: 3D Object Detection from RGB-D Image, Masahiro Takahashi, Alessandro Moro, Yonghoon, Kazunori Umeda, https://arxiv.org/ftp/arxiv/papers/2006/2006.14837.pdf
If you have any questions, please contact with tianluwu@gmail.com